






EACL 2021 的一篇论文。
0. Abstract
这篇文章重点是研究段落中的省略部分和指代部分,并将这些省略和指代语句理解为一些问答问题,可以理解为 SQuAD v1.1 式的段落跨度检索问题。
文章的主要创新就是使用问答模型处理这些省略和指代语句。实验部分分别采用训练单个省略句类型和两个省略句类型一起训练,在省略和指代问题上取得了好效果。
1. Introduction

- 图1:文章研究的主要省略语句类型,分别是疑问词省略和动词词组省略。红色的是省略词,蓝色的是省略词的指代词。
文章将省略和指代的问题转换为了 QA 问题,也就是 SQuAD v1.1 式的原文跨度检索问题。随后用 QA 模型解决这个问题。
2. Methodology
这部分介绍的比较有条理,首先介绍了两种省略语句转换为 QA 的方式,然后介绍共指解析(Coreference Resolution)和 QA 任务,之后介绍了数据构造方式,最后介绍 QA 架构。
注意,共指解析、实体消歧和实体链接都是不一样的。
共指解析和指代消解是一样的,是确定`上下文`中`代词`和`跨度`的指代关系。
实体消歧和实体统一是一样的,是确定几个`实体`是否是同一实体。
实体链接是实体消歧的一种方法,是构建实体和知识库内具体知识的链接,用知识库来帮助确定实体内容。疑问词省略句采用了来自纽约时报的 Gigaword 语料库,包含 3k 条疑问词省略句。
动词省略句采用了 WSJ part of the Penn Treebank 的动词注释。
共指解析采用了 OntoNotes 和 WikiCoref 语料库。
问答采用了 SQuAD v1.1。
数据采用 <c, q, a> 格式,对每个上下文 c,根据识别到的省略和指代词,转换为 n 个问题,并用共指解析模型找到对应的 n 个跨度,用 <ref> 和 </ref> 进行标记。
问答模型,模块是编码器模块和跨度选择模块。实验部分的编码器模块采用了 DrQA 的 LSTM 编码器、QANet 的 CNN 编码器和 BERT 编码器。
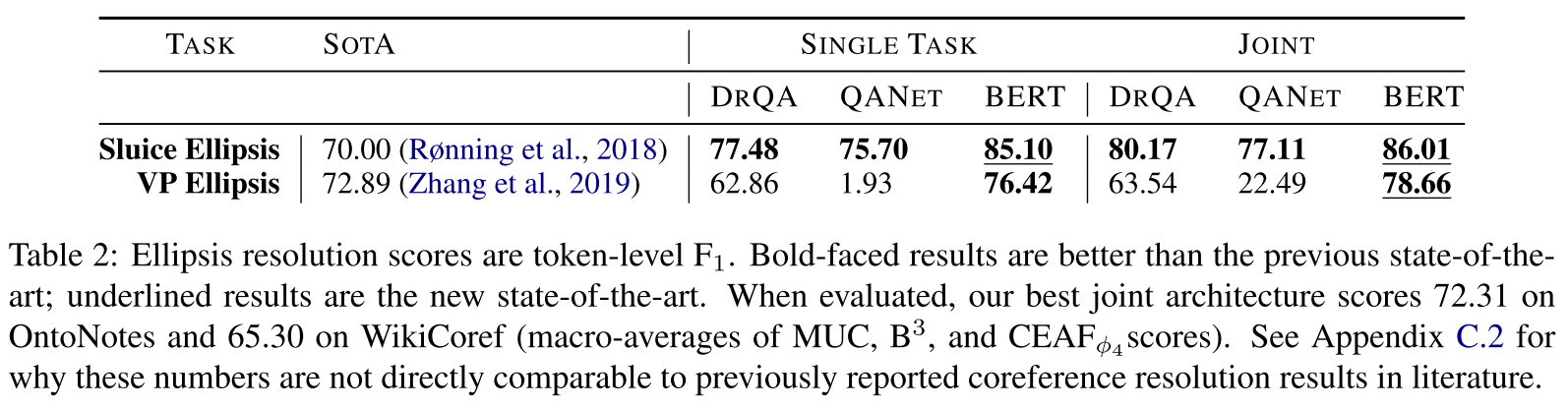
- 表2:问答模型效果,BERT 无悬念的赢了。
3. Experiments & Results
实验包括两种:单任务实验和联合实验。单任务就是分别训练两种省略句的指代模型。
联合实验效果更好。
4. Dataset Ablations
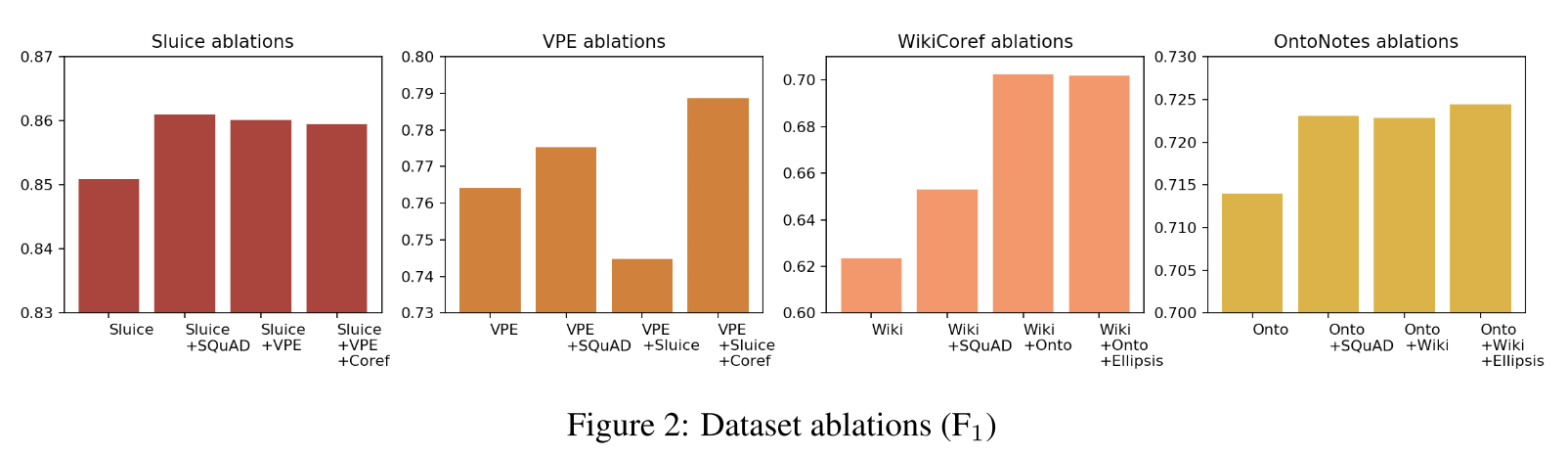
- 图2:数据集消融实验,评价指标是 F1 值。
5. Error Analysis
省略和指代语句可能会指代上下文之外的内容,或者暗示的内容。

- 图3:误差分析。
6. Related Work
7. Conclusion
将省略句的指代问题转换为问答问题,效果得到明显改善。
8. My Paper Analysis
这篇文章创新点不是很突出,不过将问题转换为问答的思路比较好,可以借鉴。
Comments | NOTHING